


0x10. Python - Network #0
Bash - Python - Scripting - Back-end - API - cURL

What a URL is ?
URL, or Uniform Resource Locator, is a string of characters used to specify the address and location of a resource on the internet.
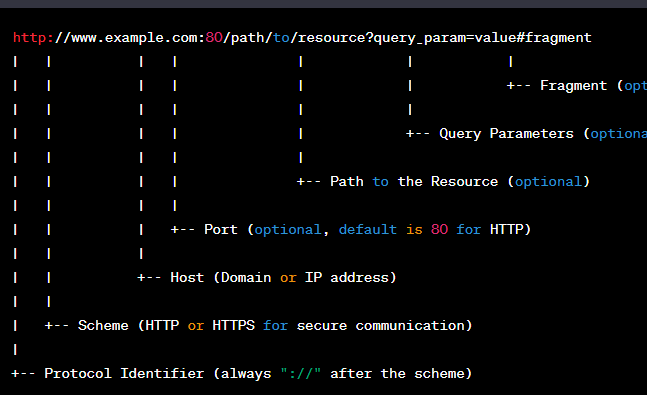
A URL typically consists of several components:
1. **Scheme**: This specifies the protocol or method used to access the resource. Common schemes include "http," "https," "ftp," "mailto," and "file."
2. **Host**: This identifies the domain or server where the resource is located. It can be an IP address or a domain name (e.g., "www.example.com" or "192.168.1.1").
3. **Port**: An optional component that specifies the port number to use when connecting to the server. If not specified, default ports are used (e.g., 80 for HTTP, 443 for HTTPS).
4. **Path**: The path specifies the location of the specific resource on the server. It follows the hostname and is separated by slashes (e.g., "/products/page1.html").
5. **Query**: An optional component that can contain parameters used to query the resource. Query parameters are separated from the path by a question mark (e.g., "?id=123&name=example").
6. **Fragment**: Another optional component that identifies a specific section or anchor within the resource. It is separated from the URL by a hash symbol (e.g., "#section1").
Here's an example of a URL and its components:
```
https://www.example.com:8080/products/page1.html?id=123&name=example#section1
```
In this URL:
- Scheme: "https"
- Host: "www.example.com"
- Port: "8080"
- Path: "/products/page1.html"
- Query: "?id=123&name=example"
- Fragment: "#section1"
URLs are essential for navigating the web and accessing various online resources, making them a fundamental concept in web development and internet technology.
What HTTP is ?
HTTP is an application layer protocol that enables the transfer of data and documents between clients (typically web browsers) and servers (web servers) on the internet.
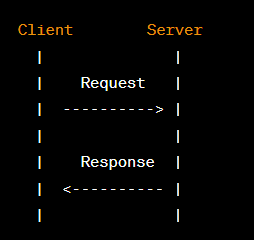
Client-Server Model: HTTP follows a client-server architecture, where a client (e.g., a web browser) sends requests to a server (e.g., a web server), which processes the request and sends back a response.
Methods: HTTP defines various request methods (HTTP verbs) that indicate the intended action for a resource. Common methods include GET (retrieve data), POST (submit data to be processed), PUT (update a resource), DELETE (remove a resource), and more
Headers: Both requests and responses can include headers, which provide metadata about the request or response. Headers can convey information such as content type, caching directives, authentication details, and more.
The scheme for a HTTP URL
In an HTTP URL, the scheme is "http," and it's followed by "://" to separate it from the rest of the URL. The scheme tells the web browser or client software that it should use the HTTP protocol to retrieve the resource specified in the URL.
For example, in the URL
http://www.example.com
the scheme is "http," indicating that the resource should be fetched using the HTTP protocol.
What a sub-domain is?
Subdomains are often used to host different content or services on a single domain. For example:
blog.example.com
shop.example.com
From a search engine optimization (SEO) perspective, subdomains can be useful for targeting specific keywords or topics, as search engines may treat them as separate entities.
What a query string is ?
Query Parameters: These are optional key-value pairs separated by ampersands ("&"). They are used to pass additional information to the server
https://example.com/path/to/resource?param1=value1¶m2=value2How to make a request with cURL
To make a request with cURL (Client for URLs), you can use the following command:
```bash
curl [options] [URL]
```
Here are some common options and examples:
1. **Basic GET Request**:
```bash
curl https://example.com
```
2. **Specify the HTTP Method**:
```bash
curl -X POST https://example.com
```
3. **Include Headers**:
```bash
curl -H "Content-Type: application/json" https://example.com
```
4. **Include Data in a POST Request**:
```bash
curl -X POST -d "key1=value1&key2=value2" https://example.com
```
5. **Follow Redirects**:
Following all redirects means that when you make an HTTP request to a URL and the server responds with a redirection status code (e.g., 301 or 302), your client (e.g., a web browser or cURL) automatically follows the redirection and makes a new request to the new URL specified in the redirection response. This process can happen recursively if there are multiple redirections in a chain, until a non-redirection response (e.g., 200 OK) is received or a maximum number of redirects is reached.
```bash
curl -L https://example.com
```
6. **Save Response to a File**:
```bash
curl -o output.html https://example.com
```
7. **Include Basic Authentication**:
```bash
curl -u username:password https://example.com
```
8. The `curl` to set a cookie with a key-value pair is `-b` or `--cookie`.
You can use this option to include a cookie in your HTTP request. Here's the basic syntax:
```
curl -b "key=value" URL
```
For example, if you want to send a request to a URL with a cookie named "session" with the value "abc123," you would use:
```
curl -b "session=abc123" URL
```
This tells `curl` to include the "session=abc123" cookie in the request headers when accessing the specified URL.
9. CURL the progression display,
In cURL, the progression display, often referred to as the progress meter, is a feature that shows the progress of data transfers during an HTTP request. It displays a progress bar with information about the transfer speed, the percentage completed, and the estimated time remaining.
The cURL option to disable the progression display is `-s` or `--silent`. When you include this option in your cURL command, it suppresses the progress meter, and cURL will execute silently without displaying the progress information. Here's how you can use it:
```bash
curl -s [URL]
```
For example:
```bash
curl -s https://example.com
```
10. CURL to delete:
To send a DELETE request using `curl`, you can use the `-X` option to specify the HTTP method as DELETE. Here's the basic syntax:
```bash
curl -X DELETE <URL>
```
For example, if you want to send a DELETE request to `https://example.com/resource/123`, you would use:
```bash
curl -X DELETE https://example.com/resource/123
```
When a client makes an HTTP request, it can include one or more "Cookie" headers to send cookies associated with the domain to the server. These cookies are typically used for session management and user authentication.
For example, an HTTP request with cookies might look like this:

The "Set-Cookie" header is included in the HTTP response sent by the server to instruct the client's browser to store a cookie. Cookies are small pieces of data that the server can use to maintain session information or track user preferences.
Here's an example of an HTTP response with the "Set-Cookie" header:

HTTP response headers Examples :
The "Status-Line" consists of the HTTP version, a three-digit status code, and a reason phrase, and it appears at the beginning of an HTTP response.
Here's the general format of a "Status-Line" in an HTTP response:
HTTP/1.1 200 OKIn this example, "HTTP/1.1" is the HTTP version, "200" is the status code (indicating a successful response), and "OK" is the reason phrase providing a brief description of the status.
Allowed HTTP methods for a URL is called "Allow." The "Allow" header indicates which HTTP methods are allowed for the specified resource. It provides a comma-separated list of the HTTP methods that can be used on that resource.
For example, if you receive an HTTP response with the "Allow" header like this:
Allow: GET, POST, PUT, DELETEIt means that for the requested resource, the allowed HTTP methods are GET, POST, PUT, and DELETE. This header helps clients (e.g., browsers or applications) understand which actions they can perform on the resource based on the server's permissions and configurations.
What happens when you type google.com in your browser (Application level)
When you type "google.com" in your web browser's address bar and hit Enter, several steps occur at the application level to load the Google website:
1. **DNS Resolution**:
- Your browser sends a DNS (Domain Name System) resolution request to your operating system. It asks the OS to resolve the domain name "google.com" into an IP address.
- The OS checks its local DNS cache. If the IP address is not found there, it forwards the request to a DNS resolver.
2. **DNS Resolution by DNS Resolver**:
- The DNS resolver (often provided by your ISP) receives the request and checks its cache for the IP address of "google.com."
- If the resolver doesn't have the IP address in its cache or it's expired, it performs a series of DNS queries to find the authoritative DNS server for "google.com."
3. **Query to Authoritative DNS Server**:
- The DNS resolver sends a query to the authoritative DNS server responsible for "google.com." This server is managed by Google.
- The authoritative DNS server responds with the IP address associated with "google.com," such as 172.217.1.46.
4. **Establishing a TCP Connection**:
- With the IP address obtained, your browser initiates a TCP (Transmission Control Protocol) connection to the server at that IP address on port 80 (HTTP) or port 443 (HTTPS).
5. **HTTP/HTTPS Request**:
- Your browser sends an HTTP or HTTPS request to the server at the IP address, specifying the domain name "google.com" and the specific resource (in this case, the homepage "/").
6. **Server Processing**:
- Google's web server processes the request and generates an HTML page for the Google homepage.
7. **HTTP/HTTPS Response**:
- The server sends an HTTP or HTTPS response containing the HTML, along with other resources like CSS, JavaScript, and images, to your browser.
8. **Rendering the Page**:
- Your browser receives the response and begins rendering the Google homepage. It parses the HTML, loads external resources, and renders the page as you see it.
9. **User Interaction**:
- You can interact with the loaded webpage, such as entering a search query or clicking on links.
when you type "google.com" in your browser, it triggers a series of steps involving DNS resolution, establishing a connection to the server, sending an HTTP/HTTPS request, receiving a response, and rendering the webpage for you to interact with. This process happens at the application level and is crucial for retrieving and displaying web content.
Resources