


0x11. Python - Network #1
Python - Scripting - Back-end - API

Fetching URLs
Fetching URLs refers to the process of making HTTP or HTTPS requests to web addresses (Uniform Resource Locators) to retrieve web content, such as web pages, documents, images, or data, from remote servers. This process is commonly used in web development, data retrieval, and automation tasks. Here's how it works:
1. **URL**: A URL is a string that specifies the location of a resource on the internet. It typically includes the protocol (HTTP or HTTPS), domain name (e.g., www.example.com), path (e.g., /page), and query parameters (e.g., ?id=123). For example, "https://www.example.com/page?id=123" is a URL.
2. **HTTP Request**: To fetch a URL, a client (e.g., a web browser, a script, or an application) sends an HTTP request to the server specified in the URL. The request includes the HTTP method (e.g., GET, POST), the URL itself, headers (e.g., user-agent, accept-encoding), and, for some methods, a request body.
3. **Server Response**: The server processes the request and sends an HTTP response back to the client. The response contains an HTTP status code (e.g., 200 for success, 404 for not found), response headers (e.g., content-type, content-length), and the requested content (e.g., HTML, JSON).
In summary, fetching URLs involves making HTTP requests to remote servers to retrieve web resources, which can be web content, data, or files, based on the provided URL.
URL schemes
also known as URI (Uniform Resource Identifier) schemes or protocol schemes, used to specify how to access or interpret a resource on the internet. A URL scheme is the part of a URL that defines the protocol or method to be used when accessing the resource. It usually appears at the beginning of a URL and is followed by a colon (":").
Here are some common URL schemes and their meanings:
http://: This scheme is used for Hypertext Transfer Protocol (HTTP) resources. It's the standard protocol for web browsing and accessing web pages. For example, "
http://www.example.com
https://www.example.com
ftp://: This scheme is for File Transfer Protocol (FTP) resources. It's used for uploading and downloading files from FTP servers. For example, "ftp://ftp.example.com" specifies an FTP resource.
file://: This scheme is used to access local files on a system. It's often used for accessing files on the local file system, and the URL typically includes the file path. For example, "file:///path/to/local/file.txt" is a file resource.
mailto:: This scheme is used for email addresses. Clicking a "mailto" link opens the user's default email client with the specified email address. For example, "mailto:user@example.com" creates an email resource.
How to fetch internet resources with the Python package urllib ?
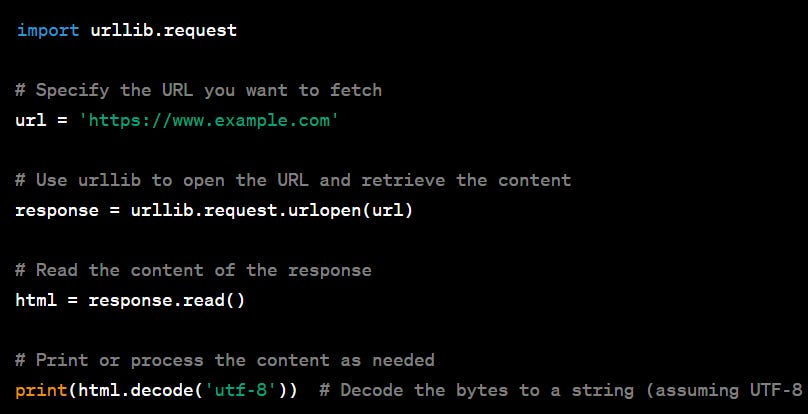
response.read(). This returns the content as bytes. We decode the bytes to a string using .decode('utf-8'). The encoding 'utf-8' is commonly used for web pages, but you should adjust it if the page uses a different encoding.How to decode urllib body response ?
To decode the body of a response obtained using urllib in Python, you can use the .decode() method to convert the bytes to a string. The specific encoding used for decoding depends on the character encoding of the content you are retrieving. Commonly, web pages use the UTF-8 encoding. Here's how to decode the response body:

urllib.request.urlopen(url) and read it as bytes with response.read().We then decode those bytes into a string using .decode('utf-8'), assuming that the content is encoded in UTF-8.How to use the Python package requests ?
The requests library in Python provides a simpler and more user-friendly way to work with HTTP requests compared to urllib. Here's a basic example of how to use requests to fetch a web page and decode the response:
First, you'll need to install the requests library if you haven't already. You can do this using pip:
pip install requestsNow, you can use requests to fetch internet resources:
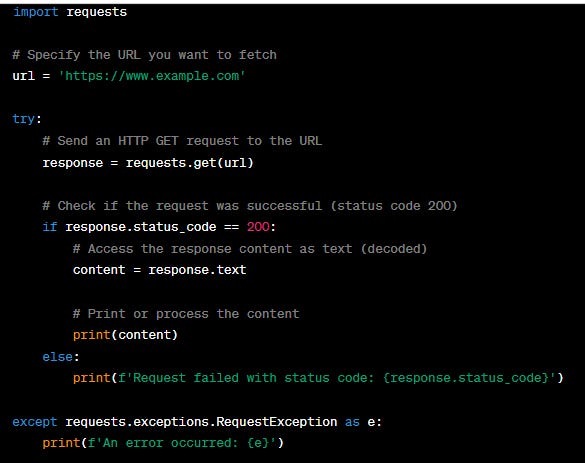
response.text - The content is already decoded into a string.How to make HTTP GET request ?
To make an HTTP GET request in Python, you can use the `requests` library, which provides a straightforward way to send HTTP requests and handle responses. Here's how you can make an HTTP GET request:
1. Install the `requests` library if you haven't already:
```bash
pip install requests
```
2. Use the following code to make an HTTP GET request:
```python
import requests
# Specify the URL you want to send the GET request to
url = 'https://example.com' # Replace with your desired URL
try:
# Send the GET request
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content as text
content = response.text
# Print or process the content
print(content)
else:
print(f'Request failed with status code: {response.status_code}')
except requests.exceptions.RequestException as e:
print(f'An error occurred: {e}')
```
How to make HTTP POST/PUT/other requests ?
To make HTTP POST, PUT, or other request types in Python using the requests library, you can use the requests.post(), requests.put(), or the relevant method for the HTTP request type you need. Here's an example of how to make different types of requests:
HTTP POST Request:

HTTP PUT Request:

In addition to the commonly used HTTP methods like GET, POST, and PUT, there are several other HTTP methods that are used in specific scenarios:
1. **DELETE**: The DELETE method is used to request the removal of a resource on the server.
2. **PATCH**: The PATCH method is used to apply partial modifications to a resource. It's often used to update specific fields of a resource without affecting the entire resource.
3. **HEAD**: The HEAD method is similar to GET, but it only requests the headers of the response, not the body. It's often used to check if a resource has changed without downloading the full content.
4. **OPTIONS**: The OPTIONS method is used to describe the communication options for the target resource. It can be used to retrieve information about the communication options supported by the server.
5. **TRACE**: The TRACE method is used for diagnostic purposes. It echoes the received request, allowing a client to see what changes or additions have been made by intermediate servers.
6. **CONNECT**: The CONNECT method is used to establish a network connection to a resource. It's typically used for establishing a network tunnel through a proxy.
These HTTP methods are defined by the HTTP/1.1 specification, and they provide different ways to interact with resources on the web. The choice of method depends on the specific requirements of your application and the API you are working with.
How to fetch JSON resources ?
Make an HTTP GET request to the JSON resource you want to fetch using the requests.get() method. Pass the URL of the JSON resource as an argument:
url = "https://example.com/api/data.json" response = requests.get(url)Check the response status code to ensure the request was successful (status code 200):
if response.status_code == 200:
# The request was successful
json_data = response.json() # Parse the JSON response
else:
# Handle the error
print(f"Request failed with status code {response.status_code}")
Example:

Notes:
The X-Request-Id is an HTTP header field that is often used in web applications to uniquely identify individual requests. It is typically generated by the server and included in the response to a client's HTTP request.
Server Generates X-Request-Id: Upon receiving the request, the server generates a unique identifier, often a random string or a timestamp, and assigns it to the
X-Request-Idheader.
Resources: