

Intro.
A database is a structured collection of data that is organized and stored for efficient retrieval and manipulation.
Types of databases:
- Relational databases use tables to organize data and are accessed using SQL or NoSQL queries.
- Distributed databases store records in multiple locations and can be homogeneous or heterogeneous.
- Cloud databases are built in a public, private or hybrid cloud environment.
- NoSQL databases are good for dealing with large collections of distributed data.
- Object-oriented databases organize data using object-oriented programming languages.
- Graph databases store, map, and query relationships using concepts from graph theory.
- Database challenges include data security, data integrity, database performance, and database integration.
- A database management system (DBMS) enables users to create and manage a database, - DBMS helps users manipulate data, control access, and provide different views of the database.
A database replica
often referred to as a database replica set, is a copy of a database that is kept synchronized with the primary database. Replicas are typically used in database systems to achieve specific goals, such as improving performance, ensuring high availability, and enhancing disaster recovery capabilities.
The purposes and benefits of having database replicas are as follows:
High Availability: Database replicas help ensure high availability by allowing for failover. If the primary database server goes down, one of the replicas can be promoted to take its place, minimizing downtime and ensuring continuous access to the data.
Load Balancing: Replicas can distribute read operations, such as SELECT queries, to share the load and improve overall database performance. This is known as load balancing and helps prevent the primary server from becoming a performance bottleneck.
Disaster Recovery: Database replicas act as a safety net in case of catastrophic failures or data corruption. If the primary database is compromised or lost, replicas can be used to restore the data to a previous state.
Backup and Reporting: Replicas can be used for backup purposes without affecting the performance of the primary database. They are also valuable for running analytical or reporting queries, as these operations can be offloaded to replicas.
Storing database backups in different physical locations: the primary reason is disaster recovery and data protection. Storing backups in multiple physical locations provides redundancy and helps mitigate various risks, such as:
To create a MySQL user name the host name set to localhost and the password, you can follow these steps:
sudo mysql -u root -p
usesudoto avoid error : ERROR 1698 (28000): Access denied for user 'root'@'localhost'
Run the following SQL command to create the holberton_user with the specified host and password:
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';If got an error, check if user already exists:
SELECT user FROM mysql.user WHERE user = 'username';
Grant Permissions:
To allow the user to check replication status, grant the necessary privileges:
GRANT REPLICATION CLIENT ON *.* TO 'username'@'localhost';The
REPLICATION CLIENTprivilege allows the user to request information about the binary logs and their contents. This is essential for tasks like setting up and monitoring replication, which involves copying data from one MySQL server to another.
Granting the 'usernamer' at 'localhost' the privilege to interact with the replication system to monitor and manage replication processes. This is typically used when setting up and maintaining MySQL replication for tasks like copying data from one server to another for redundancy and load distribution.
Flush privileges to apply the changes:
FLUSH PRIVILEGES;
Creating a database, tables, records and a user with select permissions to created table:
Create a Database:
First, create a new database. For example, let's call it "mydatabase."
CREATE DATABASE mydatabase;Use the Database:
Switch to the newly created database to work within it.
USE mydatabase;Create a Table:
Now, create a table within the "mydatabase." For example, let's create a table named "mytable" with two columns, "id" and "name."
CREATE TABLE mytable ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) );Insert a Record:
Add a record to the "mytable" table. You can insert values as needed.
INSERT INTO mytable (name) VALUES ('Example Record');Grant permissions to the 'shaza user' for the 'mydatabase' database: Example
GRANT ALL PRIVILEGES ON mydatabase.* TO 'shaza'@'localhost'Grant SELECT Permissions on certain table:
Finally, grant SELECT permissions on the "mytable" table to the user "shaza."
GRANT SELECT ON mydatabase.mytable TO shaza;Now, you have created a database, added a table to it, inserted a record, and granted SELECT permissions to the "shaza" user for the table. The "shaza" user can now query the "mytable" table within the "mydatabase."
Primary-replica cluster: “master-slave”:
A primary-replica cluster, also known as a master-slave cluster or primary-secondary cluster, is a type of architecture used in various distributed computing and database systems. It consists of two or more servers, where one server acts as the primary (or master) and the others as replicas (or slaves). This architecture is commonly used for achieving specific goals such as high availability, load balancing, and fault tolerance. Here's how it works:
Primary Server (Master):
The primary server is considered the authoritative source of data.
It handles write operations and is responsible for managing the primary copy of the data.
Any updates or changes to the data are made on the primary server.
Replica Servers (Slaves):
Replica servers maintain a copy of the data from the primary server.
They handle read operations, such as SELECT queries, and serve as backup or standby systems.
Data on replica servers is synchronized with the primary server to ensure that it stays up-to-date.

Resource : https://www.researchgate.net/figure/Master-slave-architecture_fig1_317299391

log_bin and relay-log:
log_bin (Binary Log):
log_bin, short for binary log, is a MySQL server setting that enables binary logging. Binary logging records SQL statements or changes made to the database in a binary format. These logs are a critical part of MySQL's replication, recovery, and auditing mechanisms. Here's what binary logs are used for:
Replication: Binary logs are essential for MySQL replication. They contain the changes made to the database, which are then sent to replica servers to keep them in sync with the primary server.
Point-in-Time Recovery: Binary logs are used to restore a MySQL database to a specific point in time. This is useful in data recovery scenarios.
Data Auditing: Binary logs can be used for auditing and tracking changes made to the database, providing a history of SQL statements executed.
Relay-log (Relay Log):
When data is replicated from the primary to the replica, it passes through the relay log on the replica server. Here's the purpose of the relay log:
Temporary Storage: The relay log is used as temporary storage on the replica server to store replicated events from the primary server.
Executing Changes: SQL statements from the relay log are executed on the replica server, which applies the changes to its local database to keep it synchronized with the primary server.
Redundancy: Relay logs provide a level of redundancy and allow replica servers to apply changes gradually, even if there are network issues or temporary disconnects from the primary server.
The configuration for relay-log is typically set on the replica server to specify where to store relay logs.
Creating users for a replica:
Note:
Creating a new user for the replica server with the host name set to '
%' means that the user can connect to the MySQL server from any host or IP address.The '%' wildcard character is used to allow connections from any location. This is typically done for replication purposes, as the replica server could be on a different machine or have a dynamic IP address.
Command should be like :
CREATE USER 'replica_user'@'replica_server_ipor%wild card' IDENTIFIED WITH mysql_native_password BY 'password';
This command grants the 'REPLICATION SLAVE' privilege to 'replica_user' from any host ('%'). This privilege is essential for a user connecting from the replica server to act as a replication slave.
Giving the replica_user the appropriate permissions to replicate the primary MySQL server:
The replica_user should have the following permissions for replication:
REPLICATION SLAVE: This permission allows the user to connect to the primary server as a replication slave.
REPLICATION CLIENT: This permission is necessary for the user to request information about binary logs and their contents, which is essential for replication setup and monitoring.
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replica_user'@'%';
Note : replica_user" is a common naming convention for a user account that is specifically created to be used by a replication slave server to connect to a replication master server.
Setting up a primary-replica (master-slave) configuration for MySQL on an Ubuntu server involves several steps:
Prerequisites:
Two Ubuntu servers (primary and replica).
MySQL Server installed on both servers.
Setting up a primary-replica (master-slave) configuration for MySQL on an Ubuntu server involves several steps. This configuration is useful for improving database availability, providing data redundancy, and load balancing read operations. Here's a high-level overview of the process:
**Instructions:**
1. **Configure the Primary Server (Master):**
a. Open the MySQL configuration file on the primary server using a text editor. You can use the following command:
```bash
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf
```
b. Find the `[mysqld]` section in the file and add the following lines to specify the server as the master:
```ini
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
binlog_do_db = your_database_name
```
Replace `your_database_name` with the name of the database you want to replicate.
c. Save the file and exit the text editor.
d. Restart the MySQL service:
```bash
sudo service mysql restart
```
2. **Create a MySQL User for Replication:**
a. Log in to the MySQL shell on the primary server:
```bash
mysql -u root -p
```
b. Run the following commands to create a user and grant replication privileges:
```sql
CREATE USER 'repl_user'@'replica_ip' IDENTIFIED BY 'your_password';
GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'replica_ip';
FLUSH PRIVILEGES;
```
Replace `'repl_user'` with the username you want, `'replica_ip'` with the IP address of the replica server, and `'your_password'` with a strong password.
c. Exit the MySQL shell.
3. **Configure the Replica Server:**
a. Open the MySQL configuration file on the replica server:
```bash
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf
```
b. Find the `[mysqld]` section and add the following lines to configure the replica:
```ini
server-id = 2
relay-log = /var/log/mysql/mysql-relay-bin
log_bin = /var/log/mysql/mysql-bin.log
```
c. Save the file and exit the text editor.
d. Restart the MySQL service on the replica server:
```bash
sudo service mysql restart
```
4. **Initialize the Replication on the Replica Server:**
a. Log in to the MySQL shell on the replica server:
```bash
mysql -u root -p
```
b. Run the following SQL commands to set up replication:
```sql
STOP SLAVE;
CHANGE MASTER TO MASTER_HOST='primary_server_ip', MASTER_USER='repl_user', MASTER_PASSWORD='your_password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=101;
START SLAVE;
```
Replace `'primary_server_ip'` with the IP address of the primary server, `'repl_user'` and `'your_password'` with the MySQL user and password created for replication.
5. **Monitor Replication:**
To monitor the replication status, you can use the following MySQL command on the replica server:
```sql
SHOW SLAVE STATUS\G
```
Check the `Slave_IO_Running` and `Slave_SQL_Running` fields. If they both say "Yes," replication is working correctly.
That's it! You've set up a primary-replica configuration for MySQL on Ubuntu. The primary server will now replicate its data to the replica server, providing data redundancy and load balancing for read operations.
`mysqldump`
A command-line utility in MySQL that allows you to create backups of your MySQL databases.
It's a versatile tool that can be used to back up an entire database, specific tables, or even just the result of a SQL query. Here are the basic usage and options for `mysqldump`:
**Basic Usage:**
```bash
mysqldump -u [username] -p [database_name] > [backup_file.sql]
```
- `[username]`: Your MySQL username.
- `[database_name]`: The name of the database you want to back up.
- `[backup_file.sql]`: The name of the file where the backup will be saved.
You will be prompted to enter your MySQL password after running this command.
**Common Options and Examples:**
1. **Backup a Single Database:**
To back up an entire database, use the `-B` or `--databases` option, followed by the database name. For example:
```bash
mysqldump -u [username] -p --databases [database_name] > [backup_file.sql]
```
2. **Backup Multiple Databases:**
To back up multiple databases, list the database names separated by spaces. For example:
```bash
mysqldump -u [username] -p --databases [db1] [db2] > [backup_file.sql]
```
3. **Backup All Databases:**
To back up all databases on the MySQL server, use the `--all-databases` option. For example:
```bash
mysqldump -u [username] -p --all-databases > [backup_file.sql]
```
4. **Backup Specific Tables:**
To back up specific tables within a database, list the table names after the database name. For example:
```bash
mysqldump -u [username] -p [database_name] [table1] [table2] > [backup_file.sql]
```
Developing a Backup Strategy
1. Understanding Your Backup Requirements:
- Identify recovery point objective (RPO) and recovery time objective (RTO)
- Meet with data owners to determine backup requirements
2. Offsite, Onsite and Secondary Backup Locations:
- Consider where to store backup files onsite and offsite
- Copy backups to secondary location for redundancy
3. How Long Should You Keep Those Backup Copies?:
- Assess your environment to determine how long to keep backups
- Balance recovery needs with available disk space
4. Types of Backups:
- Different backup types: FULL, DIFFERENTIAL, TRANSACTION LOG, FILE, PARTIAL
- Choose backup types based on data recovery needs
5. Building a Backup Solution:
- Consider options: COTS solution, maintenance plan, homegrown solution
- Evaluate merits of each option based on backup requirements
6. Consider Maintenance of Home-Grown Backup Solution:
- Building a home-grown backup solution requires ongoing maintenance, unlike vendor-provided solutions.
- Consider the additional effort and resources needed for maintaining the backup solution long-term.
7. Verify the Restorability of Backups:
- Perform occasional restores of databases from backups to ensure their restorability.
- Test restoring backups in a non-production environment to validate their functionality.
8. Use 'BACKUP VERIFYONLY' Command for Backup Verification:
- Utilize the 'BACKUP VERIFYONLY' command to check the correctness of backup files.
- This command reads the backup file and confirms if the data can be restored.
9. Consider Complete Bare Metal Restore:
- Perform complete bare metal restores to validate the ability to restore OS, SQL Server software, and all databases including system databases.
- A full server restore builds confidence in backup strategy and reduces anxiety during real disaster scenarios.
10. Ensure Security of Backup Files:
- Carefully choose a secure location for storing backups to prevent unauthorized access.
- If databases contain sensitive data, consider encrypting backups or restricting access to authorized personnel.
11. Consider Safety in Numbers:
- When developing a backup strategy, determine the desired recovery point objective (RPO) and recovery time objective (RTO).
- Having extra backups provides an additional sense of security. It's better to have more backups than not enough.
Setup a Primary-Replica infrastructure using MySQL:
MySQL Primary on server A:
The primary MySQL server, which contains the original data, will serve as the source of truth for the data.
No Bind-Address for Primary:
The
bind-addressparameter in MySQL specifies the network interface that the server should listen on for incoming connections. By not specifying it, you allow MySQL to listen on all available network interfaces, which is often suitable for primary serversThe location of the MySQL configuration file can vary depending on your MySQL version and system,
sudo nano /etc/mysql/my.cnfor could be in :
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf

sudo service mysql restart

MySQL Replica on server B:
The replica MySQL server, which replicates data from the primary, should be hosted on the "B" server. The replica server is responsible for copying and maintaining a synchronized copy of the data from the primary server
The
server-idis a unique identifier for each MySQL server in a replication setup. It's crucial to set a distinctserver-idfor the replica to differentiate it from other servers in the replication topology.
Binary Logging: On your MySQL master server (A), make sure binary logging is enabled.
log_bin = /var/log/mysql/mysql-bin.log
Add or Modify the binlog_do_db Setting: Inside the configuration file, locate the binlog_do_db setting and add the name of database to it. If it's not there, add the entire line. If it's there, update it.
binlog_do_db = tyrell_corp
Example:

Configuring the replica server (B)
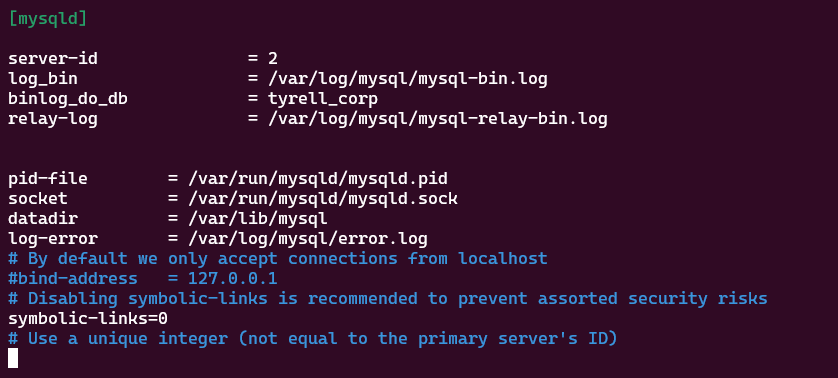
Start the MySQL service:
sudo service mysql startNotes:
log_bin = /var/log/mysql/mysql-bin.log:This setting specifies the location and filename for the binary log file. The binary log contains a record of all changes to the database, which is essential for replication. It's typically used to replay transactions on the replica server to keep it in sync with the primary.
binlog_do_db = db:Here, you specify the name of the database that you want to replicate from the primary server to the replica. In your case, it's set to 'db', but in your actual configuration, it should be 'tyrell_corp', which is the database you want to replicate.
relay-log = /var/log/mysql/mysql-relay-bin.log:The relay log is used on the replica server to store transactions received from the primary. It's important for tracking changes before they are applied to the replica's database.
very important: UFW is allowing connections on port 3306 (default MySQL port)
1. **Check UFW Status:**
First, you should check the status of UFW to see if it's enabled or not. You can do this with the following command:
```
sudo ufw status```
If UFW is not enabled, you can enable it using `sudo ufw enable`.
2. **Allow MySQL Port:**
To allow connections on port 3306, use the `ufw allow` command. Here's how to allow MySQL traffic:
```
sudo ufw allow 3306/tcp```
This command allows incoming
TCP traffic on port 3306.Make sure you've specified the correct port if you've configured MySQL to use a different port.3. **Check UFW Rules:**
After adding the rule, you can verify that it's in the list of UFW rules with:
```
sudo ufw show added```
The rule for MySQL (port 3306) should be listed there.
4. **Reload UFW:**
To apply the changes, you need to reload UFW:
```
sudo ufw reload```
5. **Check UFW Status Again:**
Finally, check the UFW status again to ensure that the rule for MySQL on port 3306 is in place and that UFW is allowing connections on that port:
```
sudo ufw status```
You should see the rule for port 3306 as "ALLOW IN."
With these steps, you've configured UFW to allow incoming connections on port 3306, which is necessary for MySQL replication to function correctly. This should help ensure that replication works as expected.
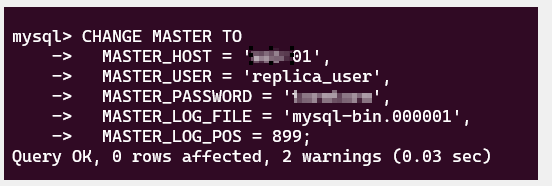
CHANGE MASTER TO:
The
CHANGE MASTER TOcommand is used to configure the replica server to connect to the primary server for replication. You need to execute this command in the MySQL command-line interface on the replica server (B). Here's how to do it:Log in to the MySQL server on web-02 (your replica server) using the following command:
mysql -u root -pYou will be prompted to enter the root user's password.
Once you are logged in, you can issue the
CHANGE MASTER TOcommand with the appropriate parameters:

CHANGE MASTER_LOG_FILE ANS MASTER_LOG_POS TO MATCH: values appear after command : show master status: example:

After executing the
CHANGE MASTER TOcommand, you can start the replication with the following command:START SLAVE;This configuration will establish the replication connection from your replica server (B) to the primary server (A).
Monitor Replication:
It's important to monitor the replication status to ensure it's working correctly. You can use the following SQL command to check the replication status:


Slave_IO_Running and Slave_SQL_Running fields to verify that replication is running without errors.“After making changes, save the configuration file and restart MySQL to apply the changes.sudo service mysql restart.”
Resources:
How to Configure MySQL Master-Slave Replication on Ubuntu Linux
Setting the correct timezone on an Ubuntu Server ensures accurate timekeeping for logs, scheduled tasks (cron jobs), and system updates. This is especially important for servers running in different geographical regions or used in distributed.
Plss visit for more information:https://docs.vultr.com/how-to-set-the-timezone-on-ubuntu-24-04
Thank you ma! We're following in your footsteps!